8장. 고급 인공신경망 구현
심층신경망은 사라지는 기울기(Vanishing Gradient)라는 한계에 부딪혔다.
층을 여러 개 쌓으면 복잡한 기능을 하는 모델을 구현할 수 있지만,
연결강도의 변화량이 0에 가까워져 연결강도가 조정되지 않는 문제가 발생했다.
해결 방법으로는
1. 활성화 함수를 바꾸기
2. 적절한 가중치 초기화
활성화 함수
1. sigmoid(시그모이드)
시그모이드의 미분값은 0일 때 max값으로 1/4를 갖는다.
오차역전파 알고리즘을 이용했을 때,
층의 개수가 많아지면 (1/4) * (1/4) * ... * (1/4) 가 계속 곱해지는데,
이는 점점 0에 가까워진다.
따라서 시그모이드 함수는 vanishing gradient라는 한계를 가지고 있다.
2. tanh(하이퍼볼릭 탄젠트)
하이퍼볼릭 탄젠트는 -1에서 1 사이의 값을 가지며, 중앙값이 0이다.
중앙값이 0이기 때문에 편향 이동이 발생하지 않는다.
vanishing gradient가 시그모이드보다는 적지만 완전히 해결해 줄 수는 없다.
3. ReLU
x<0 일 때는 0
x>=0 일 때는 x의 값을 갖는 함수
음수인 경우 미분 값이 0이기 때문에 쉽게 죽는다는 단점이 있다.
vanishing gradient 문제가 발생하지 않는다.
etc. leacky(새는) ReLU, PReLU, ECU 등
새로운 활성화 함수들은 계산 상의 이점을 강화하는 방향으로 발전
연결강도 조정식

학습률이 낮으면 학습 시간이 오래 걸리지만 안정적이다.
학습률이 높으면 빠르지만 발산하는 문제가 생길 수 있다.
모멘텀
경사하강법의 성능을 개선
연결강도를 업데이트 할 때 이전 단계의 업데이트 방향을 반영함
일종의 관성을 부여하는 것
최적화기법
Adam(적응적 모멘텀 추정 기법)
심층신경회로망
조합과 tunning을 얼마나 잘하느냐의 차이이다.
softmax
다중분류의 경우 출력층에서 활성화함수로 많이 사용한다.
결과의 합이 1이 되도록, 즉 0~1 사이의 확률 값으로 조정하는 함수
최대값을 더욱 활성화하고 작은 값을 억제하는 효과
확실하게 상대적인 크기를 나타내준다.
원-핫 인코딩
소프트맥스 함수의 출력값과 정답과의 차이를 구하기 위해 사용한다.
다분류의 경우 정답 값 하나만 1이 되고, 나머지는 0이 된다.
MSE(Mean Squared Error)
CEE(Cross Entropy Error)
분류 모델에서 MSE보다 더 유용하게 사용될 수 있다.
분류 모델의 정답값이 원-핫 인코딩으로 구성되어야 한다.
t는 target value, y는 예측치를 의미한다.
정답 값이 원-핫 인코딩 방식인 경우
정답 위치의 확률값을 제외한 나머지는 무조건 0이 나오므로
정답값에 대한 예측값 만이 결과에 영향을 주는 식이다.
MSE보다 더 민감하기에 학습 속도가 더 빠르고, 성능도 더 좋다.
정규화
sklearn의 MinMaxScaler() 사용
데이터를 0에서 1 사이의 값으로 조정
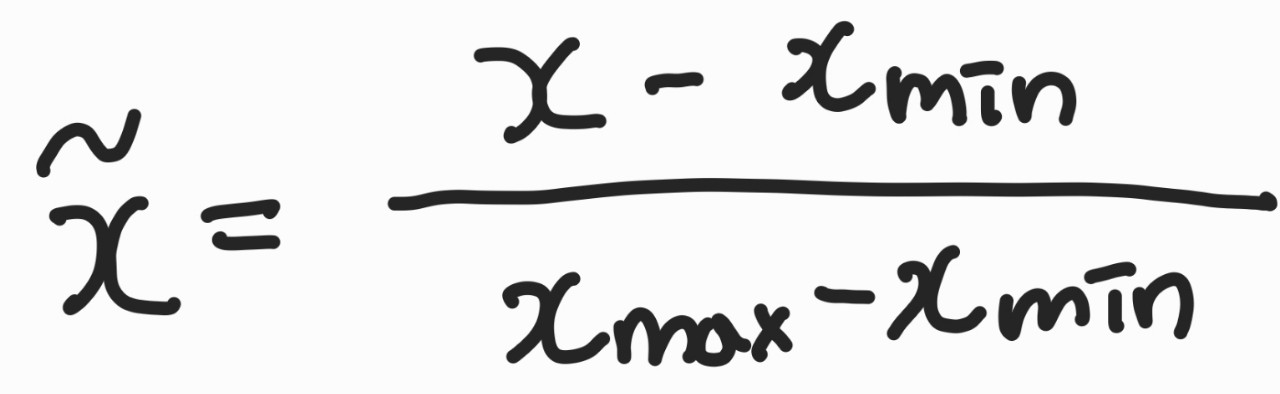
표준화
평균이 0이고 표준편차가 1인 정규분포를 가지도록 데이터를 조정
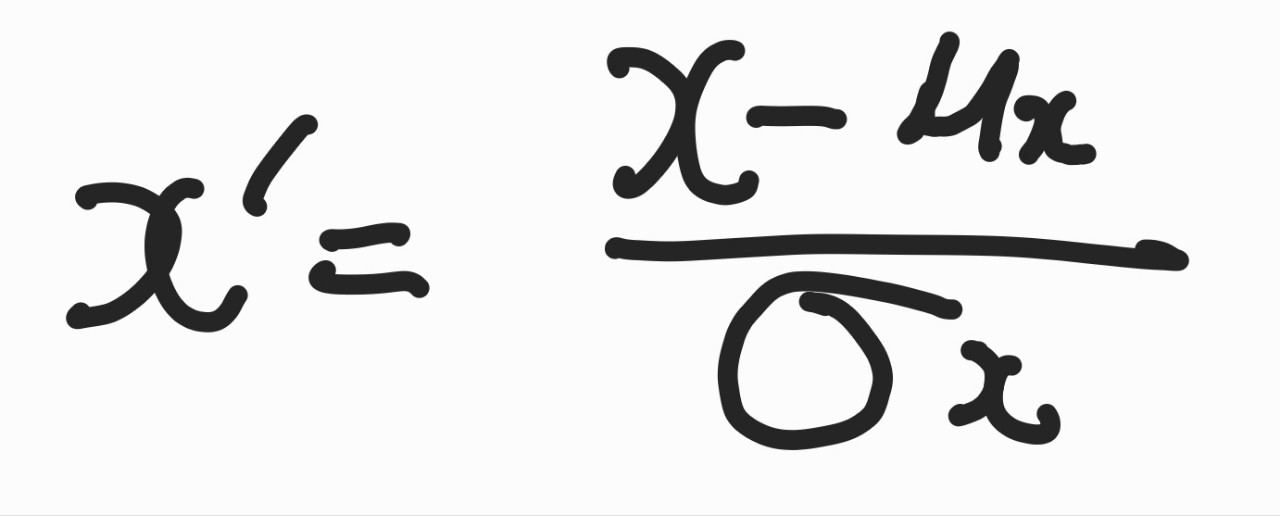
학습 데이터셋 사용 방법 3가지
1. 배치 경사 하강법
최적해를 얻는 데 너무 많은 시간이 걸린다. 안정적이다.
2. 확률적 경사 하강법(SGD)
실행 속도가 빠르다. 성능이 들쑥날쑥 변하며 학습한다.
3. 미니 배치 경사 하강법
절충안, 성능이 가장 좋다.
교차 검증(Cross Validation)
학습을 하면서 훈련에 사용되지 않은 데이터를 이용하여 교차 검증 => 더 객관적인 비교가 가능하다.
은닉층이 많아지면 훈련 데이터에만 잘 적용되는 과적합(Overfitting) 가능성
해결책
1. Dropout
임의의 노드를 탈락시켜 학습하는 것
layer = tf.keras.layers.Dropout(.3, input_shape = (2, ))0.3은 10개 중 3개의 데이터를 탈락시킨다는 것이 아니라
0.3의 확률로 데이터를 탈락시킨다는 의미이다.
탈락이 이루어진 만큼 나머지 데이터에
1/1-dropuout률 만큼 곱해진다.
2. Regularization(정칙화)
'공부 > 기계학습' 카테고리의 다른 글
| [ML] 인공지능 및 기계학습 개론 1(23.05.17) (0) | 2023.05.17 |
|---|---|
| [기계학습] 1~11주차 총정리 (0) | 2022.12.10 |
| [기계학습] 기말고사 정리 13장 (0) | 2022.12.09 |
| [기계학습] 기말고사 정리 10장 (0) | 2022.12.09 |
| [기계학습] 기말고사 정리 9장 (0) | 2022.12.09 |