11주차
CNN Architectures
1. AlexNet
- 8개의 layer
- 227 * 227 * 3 입력 이미지 해상도 고정
output size:

p는 padding의 크기
k는 kernal, filter의 크기
s는 stride
파라미터 개수
filter size * 3(3차원) * 필터 개수
pooling의 경우에는 학습해야 할 파라미터의 개수가 0이다.
softmax : normalization, 각 클래스의 값의 합을 1로 만들어준다.
-> 0과 1 사이의 확률값으로
2. VGGNet
더 작은 필터를 사용, 깊어진 network
전부 3*3 filter 사용
3개의 3*3 conv
1개의 7*7 conv
=> receptive field는 같다.
파라미터 수는 27C^2, 49C^2으로 3개의 3*3 conv가 훨씬 적다.
깊어질수록 성능이 좋아지고, 더 non-linear하게 만들 수 있다.
메모리 : 이미지 크기
파라미터 : w의 개수

7 * 7 * 512를 그대로 stretch
이를 4096으로 만들기 위해 Fully Connected 연산
=> VGG는 Fully connected 연산에서 파라미터가 많다.
AlexNet, VGGNet 모두 입력 크기를 바꿔주면 동작하지 않는다.
3. GoogleNet
깊게 만들면서도 연산적으로 효율적인
더 적은 파라미터로도 좋은 성과
FC layers 마지막 클래스 개수를 맞춰주기 위한 하나 빼고 전혀 사용 X
Inception Module

병렬적인 연산의 장점
다양한 receptive field를 추출하여 조합해 사용할 수 있다.

각각의 출력의 해상도는 동일해야 함
결과들을 depth차원에서 연결(뒤에 이어붙이기)
concatenation 후 1*1 conv를 통해 feature map을 섞어주기
Computational complexity 문제
해결책 : bottlenect layers
1*1 conv를 이용해 feature channel size를 줄인다.

출력과 비슷한 구조가 중간중간 달려있다.
깊어짐에 따라 loss가 없어지는 문제
이를 보완하기 위해 중간중간에서도 예측해서 안쪽으로 loss를 잘 전달할 수 있도록
Average Pooling이용 -> 공간적인 크기를 평균내서 1로 만들어버림
1 * 1 * c(channel)의 벡터로 만들 수 있다.(fully connected layer 필요없음)
12주차
CNN architecture
4. ResNet
layer가 급증하였다 => 깊어진다 => 효율성, 정확도가 좋아진다
152 layer, 사람 그 이상의 성능
Connections

단순하게 layer를 이어붙인다고 좋아지지 않는다.
deep model은 표현능력은 더 좋지만, loss가 사라지는 문제, optimize문제 등
Residual Block을 이용하여 해결(입력을 출력부분에도 연결해줌)
H(x) = F(x) + x
F(x) = H(x) - x
출력과 x의 차이만 학습한다.
해상도가 높아 메모리를 많이 차지하는 문제
=> 7*7 conv, /2를 통해 이미지 크기를 줄여준다.
FC layer는 마지막 한개 뿐
ResNet 50+ 의 경우
bottleneck 사용
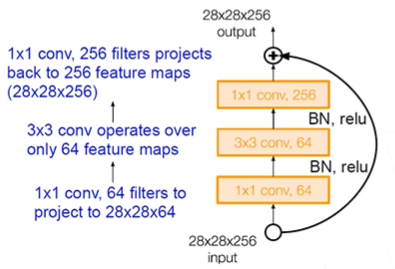
bottleneck : 1*1 conv를 통해 feature 크기를 바꿔준다.(googlenet과 유사)
Comparing Complexity
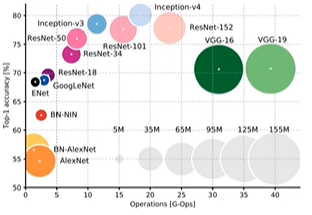
오른쪽으로 갈수록 연산량 증가
높은 곳에 위치할수록 정확도 높음
원의 면적 : 메모리
VGG : 메모리, OP가 많음 (왜?)
GoogleNet : bottleneck으로 해결 -> 메모리, OP 적음
average pooling을 통해 fully connected 연산을 최소화
AlexNet : layer얇음 -> 연산량 적다. 메모리는 fully connected이기 때문에 많이 차지
2017년 SENet
Squeeze-and-Excitation Networks
feature recalibration
feature map을 적응적으로 weight를 바꾼다.
상황에 따라 상대적으로 중요하지 않은 filter도 있을 수 있음
적용할 weight는
global average pooling과 fully connected를 이용
global pooling
채널별로 평균을 하나로 만들어주는
sigmoid : activation function 중 하나
0~1 사이 값으로 만들어줄 때 사용
Batch Normalization
미니 배치
베타 : 학습
ResNext
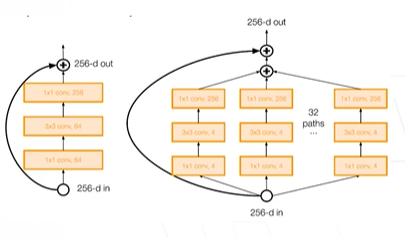
엄청 많은 conv
connection은 달려있음
inception과 유사
DenseNet
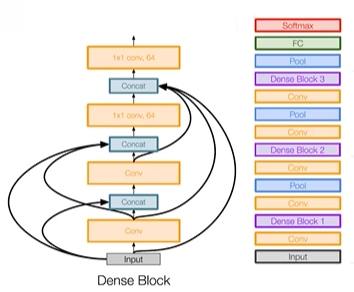
connection이 조금 더 dense하게
50개의 layer만 사용해도 resnet 152개 layer보다 성능이 좋았다.
MobileNet
가볍고, 연산량이 적은, 모바일에서 사용 가능한
convolution -> 연산량이 많다.
depthwise seperable convolution을 제안
depth를 쪼개서 본다.
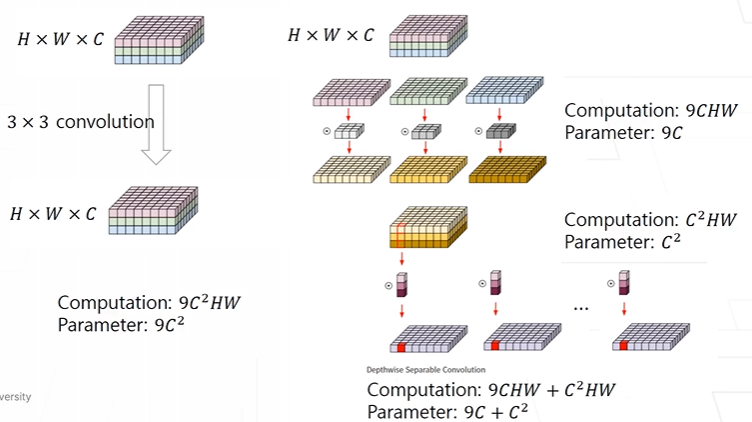
pointwise : depth를 섞어주는 과정
1 * 1 * C를 이용한 conv
전이학습
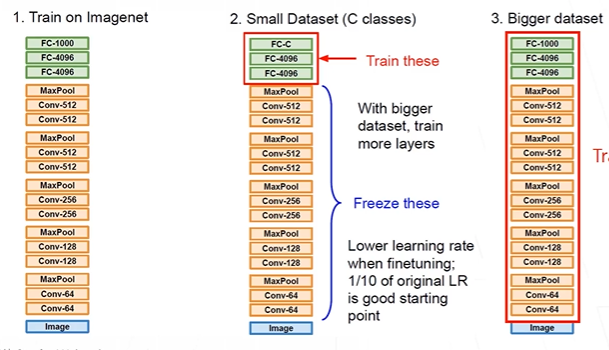
imagenet의 pretrained 파라미터를 불러와 사용
freezing : 학습이 안되게 고정
'공부' 카테고리의 다른 글
| [소프트웨어공학] 기말고사 정리 (1) | 2022.12.14 |
|---|---|
| [컴퓨터비전] 13, 14주차 정리 (1) | 2022.12.14 |
| [컴퓨터비전] 9, 10주차 정리 (0) | 2022.12.13 |
| [컴퓨터비전] 7주차 정리 (0) | 2022.12.13 |
| [컴퓨터비전] 5, 6주차 정리 (0) | 2022.12.13 |