양희철교수님 - 데이터분석
데이터 분류
- structured or unstructured
- i.i.d. data or non-i.i.d. data (i.i.d. : independent and identically distributed) (확률분포가 동일한)
- vectorial or non-vectorial data (벡터 형태)
- labeled or unlabeled data (데이터에 대해 값이 주어져 있는지)
- Images, text, languages, time series, graphs and so on
회귀(Regression)
- 비슷한 상관분석(Correlation analysis)

두 변수 사이에 상관관계가 존재하는지 파악하고 그 정도를 확인하는 것
관련성을 파악하는 지표로 상관계수를 이용, 선형적 상관도를 확인하여 정도를 파악
- 회귀분석(Regression analysis)
x, y 사이의 함수를 구하는 것
독립변수와 종속변수라고 하는 인과관계도 설명할 수 있음

데이터 x에 대한 결과 y(실수)를 통해 둘 사이의 함수 f(x)를 학습
overfitting : 너무 정확하게 모델링하려고 하면 새로운 데이터에 대한 예측값의 오차가 커지는 문제가 발생
분류(Classification)
데이터 x에 대한 결과 y(분류값)을 통해 둘 사이의 분류 함수 f(x)를 학습
불연속적
- 이미지 분류
군집화(Clustering)
데이터 사이의 숨겨진 구조를 밝혀서 비슷한 데이터들을 군집화
데이터가 레이블 되어있지 않음
비지도학습

K-means clustering
값의 차이가 최소가 되도록 clustering
AI : Machine이 사람의 행동을 흉내내도록 만드는 것
Machine Learning : 기계학습, 경험(데이터)를 가지고 통계적인 모델을 만들어 AI를 수행한다.
Deep Learning : 사람의 뉴런의 구조를 따라 만든 인공신경망으로 머신러닝을 수행하는 학습 기법
전통적 프로그래밍과 머신러닝의 차이
- 전통적 프로그래밍
사람이 프로그래밍 해줘야 함
Input : Data, Program => Output
- ML
Input : Data, Output => Program
Machine Learning
- Training(Learning)
학습의 개념이 들어가기 때문에 데이터가 필요함 => 예측을 할 수 있는 모델을 생성
실제값과 예측값의 차이를 이용해 다시 모델을 업데이트(back propagation)
- Test(Inference)
모델 사용
1. 지도학습
supervised learning
data + 원하는 output => model
ex) regression, classifiction
2. 비지도학습
unsupervised learning
training data (원하는 output은 제공 X)
숨겨진 구조나 특성을 파악
ex) clustering
3. 강화학습
reinforcement learning
행동에 따른 보상, 경험을 토대로 학습
action에 대한 결과 자체를 데이터로 봄
4. 준지도학습
지도학습과 비지도학습의 중간쯤
output은 일부만 주어짐
데이터를 수집하는 데이터 레이블링 작업에 소요되는 자원과 비용 감소

supervised learning에 비해 성능이 크게 떨어지지 않음
- proxy-label method : labeled data로 학습된 모델을 이용해 unlabeled data에 label을 달아주는 기법
5. self supervised learning(자기지도학습)
라벨링이 되어 있지 않더라도 모델 스스로 task를 정해서 지도학습처럼 학습하는 방법
- self prediction : 개별 data sample에 대해, sample 내의 한 파트를 통해서 다른 파트를 예측하는 task
- contrastive learning : batch 내의 data를 이용해 그들 사이의 관계를 예측하는 task
모델 평가
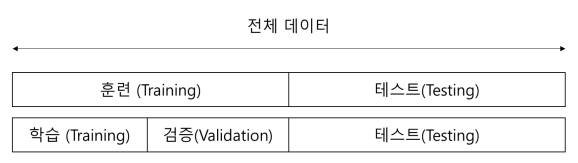
전체 데이터를 훈련용 / 테스트용 으로 분할
훈련용을 학습 / 검증 을 위한 데이터로 나누기도 함
모델 평가 지표
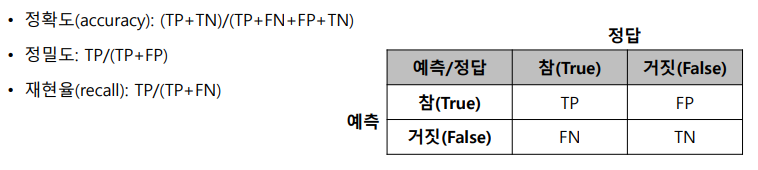
1. 정확도(accuracy) : (TP + TN) / (TP + FN + FP + TN)
2. 정밀도 : TP / (TP + FP)
3. 재현율(recall) : TP / (TP + FN)
4. ROC(Receiver Operating Characteristic)
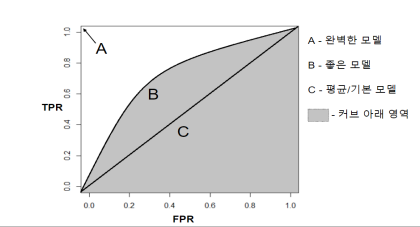
FP와 TP의 비율을 따져서 TP가 높으면 커브가 A에 가깝게, C면 50%
+ fairness 평가
이미지 데이터에 대한 공정성을 가져야 한다.
데이터 전처리
pandas 라이브러리
csv(comma separated variables)
- 2차원 표 형태
- 데이터의 중간에 구분자가 포함되어야 한다면 따옴표를 사용하여 필드를 묶어야 함
- 큰 크기의 데이터의 경우 한 번에 모든 레코드를 읽지 않는 것이 좋다.
JSON : key, value를 갖는 객체 형태로 값을 저장
판다스의 데이터 구조
- 시리즈 : 레이블이 붙어있는 1차원 벡터
- 데이터프레임 : 행과 열로 되어있는 2차원 테이블, 각 열은 시리즈로 구성
프로그래머스 - 프론트엔드 미니 데브코스
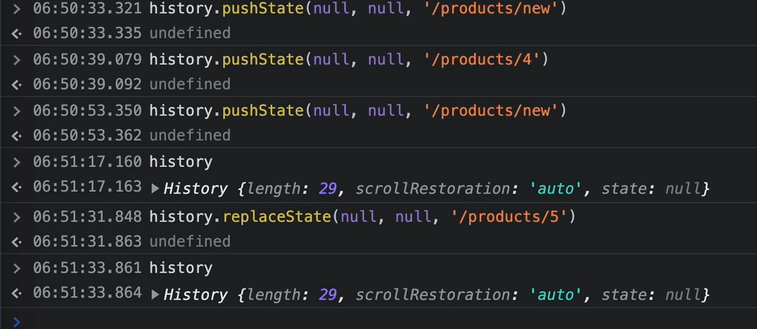
history API의 pushState, replaceState

length : 쌓여 있는 history 개수
scrollRestoration : 뒤로가기 했을 때 이전의 scroll으로 돌아갈것이냐
state : pushState, replaceState의 state값
pushState : 화면의 이동 없이 주소만 바뀜
뒤로가기, 앞으로가기 가능
href의 경우 페이지를 이동 => reload
replaceState : 바로 이전 페이지로 뒤로가기가 되지 않는 페이지를 만들 때 사용
npx http-serverpushState로 url 이동 후 새로고침 시 404 에러 발생
npx serve -s404 에러가 발생할 때 index.html로 화면을 돌려준다.

popstate 이벤트는 뒤로가기나 앞으로가기 할 때 발생

404 에러가 났을 경우 root의 index.html로 요청을 돌려주는 처리가 필요하다.
To do App 만들기
- users API를 이용해 사용자의 todo 목록 가져오기
- 할 일을 추가하면 화면에 추가되고, API 호출을 통해 서버에도 추가
- TODO를 추가하고 삭제하는 동안 낙관적 업데이트 사용
- 서버와 통신하는 동안 통신중임을 알리는 UI적 처리
Event delegation기법
상위 엘리먼트에 이벤트를 준 뒤, 분기하는 것
이벤트의 target 값을 이용해 버튼의 클릭 이벤트를 지정한다.
낙관적 업데이트
API가 잘 동작할 것이라고 낙관적으로 보고 데이터를 추가할 때 client에 바로 추가해버리고 서버에 통신하는 것
ex) 페이스북
=> 로딩중 처리가 가장 안전하기는 하다.
코딩테스트 - 성심당 작은메아리
bread1 = input()
price1 = int(input())
bread2 = input()
price2 = int(input())
if price1 > price2:
print(bread1)
else:
print(bread2)'SW Academy' 카테고리의 다른 글
| [CNU SW Academy] 26일차(23.01.05) (0) | 2023.01.05 |
|---|---|
| [CNU SW Academy] 25일차(23.01.04) (0) | 2023.01.04 |
| [CNU SW Academy] 23일차(23.01.02) (0) | 2023.01.02 |
| [CNU SW Academy] 22일차(22.12.30) (0) | 2023.01.01 |
| [CNU SW Academy] 21일차(22.12.29) (0) | 2023.01.01 |